StyleGAN — это нейросеть, генерирующая лица никогда не существовавших людей. Гверн Бранвен (Gwern Branwen), исследователь нейросетей из США, смог вывести ее на новый уровень — StyleGAN научилась создавать лица несуществующих персонажей аниме. Также он запустил свой сайт, на котором каждые 18 секунд появляется новый персонаж и сюжет аниме, сгенерированный GPT-3. В этой статье мы расскажем, как самостоятельно создать генератор аниме-персонажей, используя StyleGAN.
Немного истории
Генерация аниме-лиц в хорошем качестве — задача, которая долгое время не поддавалась искусственному интеллекту. Несмотря на успехи ИИ в создании человеческих лиц, аниме-изображения выходили расплывчатыми и похожими друг на друга. Гверн пытался обучить целый ряд генеративных нейросетей: StackGAN / StackGAN ++ & Pixel * NN *, WGAN-GP, Glow, GAN-QP, MSG-GAN, SAGAN, VGAN, PokeGAN, BigGAN 3, ProGAN и StyleGAN. Большинство попыток провалились: сети расходились после 1-2 дней обучения, создавали одних и тех же персонажей, или же просто выдавали рисунки плохого качества.
Хорошие результаты продемонстрировали нейросети BigGAN и ProGAN: они смогли создать и масштабировать четкие аниме-лица. Однако обучение ProGAN требовало много затрат и времени (около 6 GPU-недель). Поэтому решено было выбрать StyleGAN — более быструю архитектуру, на которой можно натренировать большую модель на большем наборе данных.
 Аниме-лица, созданные с помощью GAN
Аниме-лица, созданные с помощью GAN
StyleGAN стала прорывом: она выдавала результаты на уровне ProGAN, но обучалась быстрее. Нейросеть радикально отличается по архитектуре, благодаря этому потребность в медленном прогрессивном росте минимальна, возможно даже полностью устранена. Сеть эффективно обучается на изображениях с разным разрешением и позволяет контролировать создаваемые картинки с помощью механизма передачи стиля.
Примеры изображений
Рандомный персонаж аниме, созданный нейросетью:

Примеры аниме-персонажей, сгенерированных StyleGAN:
 64 лучших образца аниме-лиц с сайта «This Waifu Does Not Exist»
64 лучших образца аниме-лиц с сайта «This Waifu Does Not Exist» 100 случайно сгенерированных StyleGAN аниме-лиц
100 случайно сгенерированных StyleGAN аниме-лиц
Как вы видите, изображения получаются очень разнообразными. Помимо цвета волос, глаз, положения головы и других мелких деталей, меняется и общий стиль рисунков. Картинки могут быть похожи на мультипликационные наброски, компьютерную графику, аниме 90-х или 00-х годов, а также на рисунки акварелью, маслом или углем.
О StyleGAN
StyleGAN — генеративно-состязательная сеть, представленная в 2018 году. Она использует архитектуру GAN, которая применяется и в ProGAN, но черпает вдохновение из механизма передачи стиля. StyleGAN модифицирует свою генераторную сеть (генератор), которая создает изображение путем его многократного увеличения: 8px → 16px → 32px → 64px → 128px и так далее. На каждом уровне используется комбинация случайных входных данных — «стилевого шума» («style noise») в сочетании с AdaIN. Он сообщает генератору, как стилизовать изображения в определенном разрешении: изменить волосы, текстуру кожи и так далее. «Стилевой шум» при низком разрешении (таком как 32px) влияет на картинку глобально — к примеру, может определить длину волос, а при высоком разрешении (таком как 256px) влияет на то, как выглядят отдельные пряди. Систематически обеспечивая некоторую случайность на каждом этапе процесса создания изображения, StyleGAN может эффективно выбирать наиболее удачные варианты.
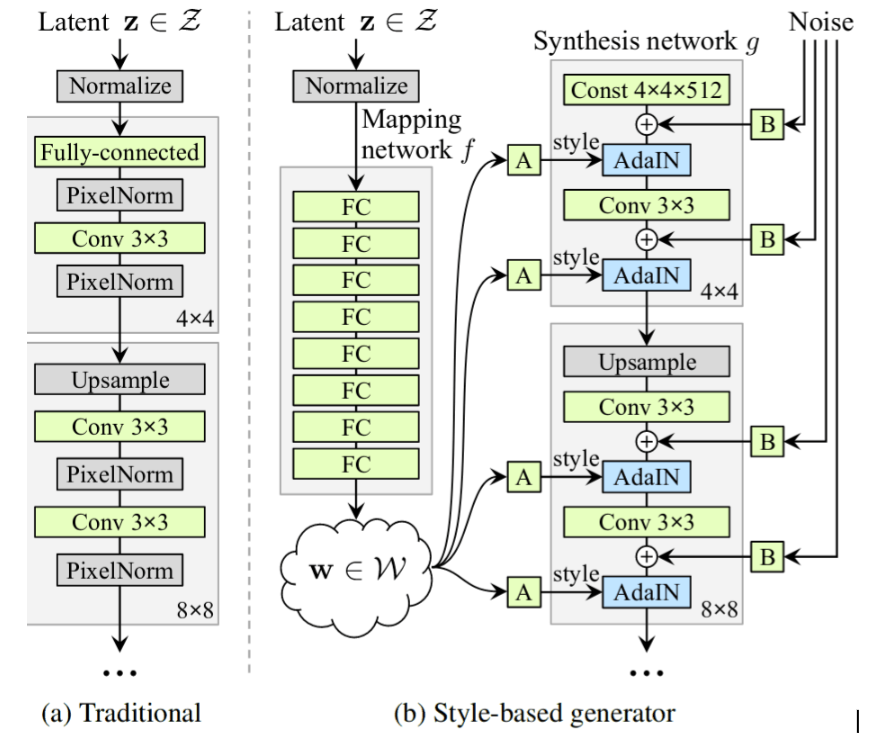 Сравнение архитектур ProGAN (a) и StyleGAN (b)
Сравнение архитектур ProGAN (a) и StyleGAN (b)
StyleGAN вносит ряд дополнительных улучшений: например, вводит новый набор данных лиц «FFHQ» с изображениями размером 1024 пикселя (больше, чем у ProGAN). Также StyleGAN демонстрирует меньше потерь и с точки зрения архитектуры необычайно интенсивно использует полносвязные слои для обработки случайного ввода — не менее 8 слоев по 512 нейронов, тогда как большинство GAN используют 1 или 2 слоя. Ещё более поразительным является то, что StyleGAN не использует методы, которые другие GAN считают критически важными для возможности обучения в масштабе 512-1024 пикселей: релятивистские потери, распределение шума, расширенная регуляризация и так далее.
В остальном же архитектура довольно обычная. Если раньше вы уже работали с какой-либо GAN, можете смело использовать StyleGAN. Процесс обучения аналогичен, гиперпараметры стандартные, а код во многом схож с ProGAN.
Применение StyleGAN
Благодаря своей скорости и стабильности StyleGAN применяется для различных задач. Вот некоторые примеры:
- «Этого человека не существует»,
- тесты: какое лицо настоящее, реальное или поддельное,
- генерация инстаграм-портретов,
- коты: «Этих кошек не существует», «Этого кота не существует» (ошибки в генерации кошек; интерполяция / передача стиля),
- гостиничные номера (с текстовыми описаниями, сгенерированными char-RNN): «Этого номера не существует»,
- «Этой вайфу не существует»,
- шрифты,
- готические соборы,
- спутниковые снимки,
- граффити,
- городские пейзажи,
- селфи из фотобудки,
- рамен,
- винные этикетки,
- портреты,
- покемоны,
- логотипы,
- текстуры Doom,
- вазы,
- футболки,
- бабочки.
 Спектр возможностей StyleGAN
Спектр возможностей StyleGAN
Что необходимо для обучения
Данные
Необходимый размер набора данных зависит от сложности задачи и от того, используется ли трансферное обучение. По умолчанию StyleGAN использует большую модель генератора, которая потенциально может обрабатывать миллионы изображений, так что чем больше данных, тем лучше.
Для создания лиц аниме-персонажей приличного качества с нуля на практике требуется как минимум 5000 картинок. Для генерации конкретного персонажа потребуется примерно 500 изображений. Для сложных задач, таких как создание несуществующих кошек, потребовалось около 1.8 миллионов снимков. Судя по многочисленным ошибкам, проблема либо в нехватке данных, либо в сложности генерации кошек.
Вычисление
Чтобы обеспечить достаточный размер мини-пакетов, вам потребуются графические процессоры с >11 ГБ видеопамяти. К примеру, для этого может подойти Nvidia 1080ti или Nvidia Tesla V100.
В репозитории StyleGAN указано расчетное время обучения для систем с 1–8 графическими процессорами. Сконвертировав их в общее количество часов работы графического процессора, мы получим следующее:
Расчетное время обучения StyleGAN для различных разрешений изображения и количества используемых GPU (источник: репозиторий StyleGAN)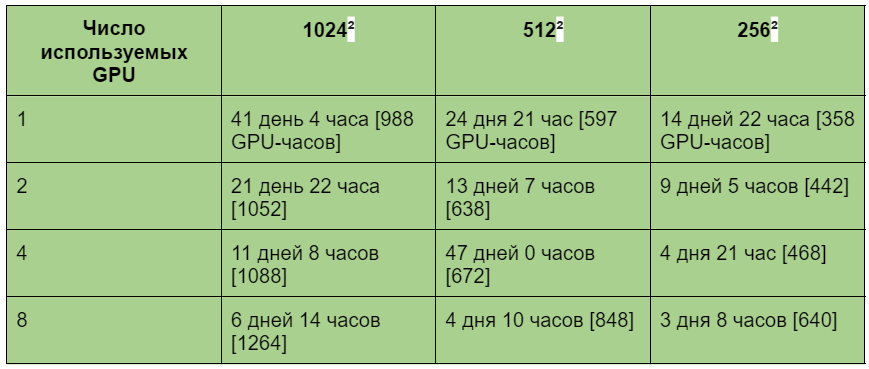
Подготовка данных
Самая сложная часть запуска StyleGAN — правильная подготовка набора данных. StyleGAN, в отличие от большинства реализаций GAN (особенно PyTorch), не поддерживает чтение каталога файлов в качестве входных данных. Он может только читать свой уникальный формат .tfrecord, в котором каждое изображение хранится в виде необработанных массивов для каждого соответствующего ему разрешения. Таким образом, исходные данные должны быть полностью однородными, преобразованными в формат .tfrecord специальным скриптом dataset_tool.py. При этом они будут занимать примерно в 19 раз больше места на диске.
Важно: набор данных StyleGAN должен состоять из изображений, отформатированных одинаково. Картинки должны быть только одинакового формата — 512×512 пикселей, 1024×1024 пикселей и так далее. Также они должны относиться к одному цветовому пространству (нельзя использовать одновременно RGB и градации серого). Изображения не должны быть прозрачными. Тип файла должен быть таким же, как у модели, которую вы собираетесь обучить/переобучить (нельзя переобучить PNG-модель на наборе данных JPG). Не должно быть скрытых ошибок, таких как ошибки контрольной суммы CRC, которые часто игнорируют программы просмотра изображений или библиотеки.
Подготовка лиц
Процесс подготовки лиц выглядит следующим образом:
- Скачайте необработанные изображения с Danbooru2018.
- Извлеките из метаданных JSON Danbooru2018 все идентификаторы подмножества изображений, если требуется определенный тег Danbooru (например, один символ), используя jq и shell-сценарии.
- Обрежьте лица персонажей на изображениях, используя метод lbpcascade_animeface от Nagadomi (обычные методы обнаружения лиц не работают на аниме).
- Удалите пустые, монохромные или чёрно-белые картинки, а также дубликаты.
- Конвертируйте изображения в JPG.
- Уменьшить разрешение до необходимого размера (512 пикселей) при помощи waifu2x.
- По возможности улучшите качество данных, проверяя изображения низкого качества вручную. Удалите и отфильтруйте с помощью предварительно обученной GAN почти полные дубликаты, найденные с помощью findimagedupes.
- Преобразуйте данные в формат StyleGAN с помощью dataset_tool.py.
Ваша цель — превратить это:
в это:

Ниже представлены shell-скрипты для подготовки набора данных. В качестве альтернативы можно использовать утилиту danbooru-utility, которая помогает исследовать набор данных, фильтровать по тегам, оценивать, обнаруживать лица и изменять размер изображений.
Обрезка
Загрузить набор данных Danbooru2018 можно через BitTorrent или rsync. Вы получите тарбол метаданных JSON, распакованный в папку metadata/2* и структуру данных {original,512px}/{0-999}/$ID.{png,jpg,...}.
Идентификаторы можно извлечь из имен файлов напрямую или из метаданных:
find ./512px/ -type f | sed -e 's/.*\/\([[:digit:]]*\)\.jpg/\1/'
# 967769
# 1853769
# 2729769
# 704769
# 1799769
# ...
tar xf metadata.json.tar.xz
cat metadata/* | jq '[.id, .rating]' -c | fgrep '"s"' | cut -d '"' -f 2 # "
# …
После установки и тестирования Nagadomi lbpcascade_animeface можно использовать простой скрипт для обрезки лиц — crop.py. Точность на изображениях Danbooru довольно хорошая: примерно 90% идеальных лиц, 5 % некачественных лиц и 5 % ошибочных, на которых вместо лиц изображены другие части тела. Точность можно улучшить, если сделать сценарий более строгим. Например, можно увеличить область интереса до размера 250×250 пикселей.
crop.py:
import cv2
import sys
import os.path
def detect(cascade_file, filename, outputname):
if not os.path.isfile(cascade_file):
raise RuntimeError("%s: not found" % cascade_file)
cascade = cv2.CascadeClassifier(cascade_file)
image = cv2.imread(filename)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
## Предлагаемая модификация: увеличьте minSize до '(250,250)' пикс.
## Это повысит число качественных лиц и уменьшит количество ложных
## срабатываний. Лица размером всего лишь 50x50px обычно либо
## бесполезны, либо вообще не лица.
faces = cascade.detectMultiScale(gray,
# Параметры детектора
scaleFactor = 1.1,
minNeighbors = 5,
minSize = (50, 50))
i=0
for (x, y, w, h) in faces:
cropped = image[y: y + h, x: x + w]
cv2.imwrite(outputname+str(i)+".png", cropped)
i=i+1
if len(sys.argv) != 4:
sys.stderr.write("usage: detect.py <input> \
<output prefix="">\n")
sys.exit(-1)
detect(sys.argv[1], sys.argv[2], sys.argv[3])
Этот скрипт может обработать лишь одно входное изображение. Обрезать все изображения параллельно можно следующим образом:
cropFaces() {
BUCKET=$(printf "%04d" $(( $@ % 1000 )) )
ID="$@"
CUDA_VISIBLE_DEVICES="" nice python \
~/src/lbpcascade_animeface/examples/crop.py \
~/src/lbpcascade_animeface/lbpcascade_animeface.xml \
./original/$BUCKET/$ID.* "./faces/$ID"
}
export -f cropFaces
mkdir ./faces/
cat sfw-ids.txt | parallel --progress cropFaces
Очистка и масштабирование
Удаление ненужных файлов происходит следующим образом:
## Удаление ошибочных и пустых файлов:
find faces/ -size 0 -type f -delete
## Удаление слишком маленьких файлов:
find faces/ -size -40k -type f -delete
## Удаление дубликатов:
fdupes --delete --omitfirst --noprompt faces/
## Удаление монохромных или малоцветных изображений: эвристика <257
### уникальных цветов несовершенна, но лучше всего, что было испробовано
deleteBW() { if [[ `identify -format "%k" "$@"` -lt 257 ]];
then rm "$@"; fi; }
export -f deleteBW
find faces -type f | parallel --progress deleteBW
Следующим важным шагом является масштабирование картинок с помощью waifu2x, которая отлично справляется с двукратным увеличением аниме-изображений. Недостатком является то, что она работает довольно медленно (1-10 секунд на изображение), запускается только на GPU и написана в неподдерживаемом на данный момент DL-фреймворке Torch.
Если нужно сэкономить время, можно масштабировать картинки с помощью ImageMagick, но их качество будет хуже.
Использование waifu2x:
. ~/src/torch/install/bin/torch-activate
upscaleWaifu2x() {
SIZE1=$(identify -format "%h" "$@")
SIZE2=$(identify -format "%w" "$@");
if (( $SIZE1 < 512 && $SIZE2 < 512 )); then
echo "$@" $SIZE
TMP=$(mktemp "/tmp/XXXXXX.png")
CUDA_VISIBLE_DEVICES="$((RANDOM % 2 < 1))" nice th \
~/src/waifu2x/waifu2x.lua -model_dir \
~/src/waifu2x/models/upconv_7/art -tta 1 -m noise_scale \
-noise_level 1 -scale 2 \
-i "$@" -o "$TMP"
convert "$TMP" "$@"
rm "$TMP"
fi; }
export -f upscaleWaifu2x
find faces/ -type f | parallel --progress --jobs 9 upscaleWaifu2x
Проверка и дополнение данных
На этом этапе можно вручную проверить качество данных: просмотреть несколько сотен изображений, запустить findimagedupes -t 99% для починки почти одинаковых лиц или же модифицировать набор с помощью дополнения данных.
Зеркальное/горизонтальное отражение выполнять не нужно, так как в StyleGAN встроена эта опция. Можно растягивать картинки, менять цвета, повышать резкость, размывать, увеличивать/уменьшать контрастность/яркость, обрезать и так далее. Пример дополнения данных:
dataAugment () {
image="$@"
target=$(basename "$@")
suffix="png"
convert -deskew 50 "$image" "$target".deskew."$suffix"
convert -resize 110%x100% "$image" "$target".horizstretch."$suffix"
convert -resize 100%x110% "$image" "$target".vertstretch."$suffix"
convert -blue-shift 1.1 "$image" "$target".midnight."$suffix"
convert -fill red -colorize 5% "$image" "$target".red."$suffix"
convert -fill orange -colorize 5% "$image" "$target".orange."$suffix"
convert -fill yellow -colorize 5% "$image" "$target".yellow."$suffix"
convert -fill green -colorize 5% "$image" "$target".green."$suffix"
convert -fill blue -colorize 5% "$image" "$target".blue."$suffix"
convert -fill purple -colorize 5% "$image" "$target".purple."$suffix"
convert -adaptive-blur 3x2 "$image" "$target".blur."$suffix"
convert -adaptive-sharpen 4x2 "$image" "$target".sharpen."$suffix"
convert -brightness-contrast 10 "$image" "$target".brighter."$suffix"
convert -brightness-contrast 10x10 "$image" \
"$target".brightercontraster."$suffix"
convert -brightness-contrast -10 "$image" "$target".darker."$suffix"
convert -brightness-contrast -10x10 "$image" \
"$target".darkerlesscontrast."$suffix"
convert +level 5% "$image" "$target".contraster."$suffix"
convert -level 5%\! "$image" "$target".lesscontrast."$suffix"
}
export -f dataAugment
find faces/ -type f | parallel --progress dataAugment
Повторное масштабирование и преобразование
После внесения каких-либо изменений или увеличения данных можно сэкономить много места на диске, преобразовав изображения в JPG и уменьшив качество с небольшими потерями. Это сэкономит много места без видимых изменений:
convertPNGToJPG() { convert -quality 33 "$@" "$@".jpg && rm "$@"; }
export -f convertPNGToJPG
find faces/ -type f -name "*.png" | parallel --progress convertPNGToJPG
Помните, что модели StyleGAN совместимы только с изображениями того типа, на котором они были обучены. Если вы используете предварительно обученную на PNG модель StyleGAN, вам нужно продолжать использовать PNG.
Далее масштабируем все изображения до размера 512х512 пикселей с помощью ImageMagick без сохранения пропорций:
find faces/ -type f | xargs --max-procs=16 -n 5000 \
mogrify -resize 512x512\> -extent 512x512\> -gravity center -background black
Любое немного отличающееся изображение может привести к сбою процесса импорта. Поэтому удаляем все изображения, которые хоть немного отличаются от 512×512 sRGB JPG:
find faces/ -type f | xargs --max-procs=16 -n 10000 identify | \
fgrep -v " JPEG 512x512 512x512+0+0 8-bit sRGB"| cut -d ' ' -f 1 | \
xargs --max-procs=16 -n 10000 rm
Теперь можно преобразовать данные в формат StyleGAN с помощью dataset_tool.py. Настоятельно рекомендуем отредактировать dataset_tool.py и добавить в этот скрипт вывод имен файлов. Если произойдет сбой, то вы сможете определить, из-за какого изображения он произошел:
diff --git a/dataset_tool.py b/dataset_tool.py
index 4ddfe44..e64e40b 100755
--- a/dataset_tool.py
+++ b/dataset_tool.py
@@ -519,6 +519,7 @@ def create_from_images(tfrecord_dir, image_dir, shuffle):
with TFRecordExporter(tfrecord_dir, len(image_filenames)) as tfr:
order = tfr.choose_shuffled_order()
if shuffle else np.arange(len(image_filenames))
for idx in range(order.size):
+ print(image_filenames[order[idx]])
img = np.asarray(PIL.Image.open(image_filenames[order[idx]]))
if channels == 1:
img = img[np.newaxis, :, :] # HW => CHW
Проблем быть не должно, если все картинки были тщательно проверены ранее.
Преобразование выполняется следующим образом:
source activate MY_TENSORFLOW_ENVIRONMENT
python dataset_tool.py create_from_images \
datasets/faces /media/gwern/Data/danbooru2018/faces/
Обучение модели
Установка
Предполагается, что у вас установлена и работает CUDA. Автор использовал ОС Ubuntu Bionic 18.04.2 LTS, драйвер Nvidia версии № 410.104, CUDA 10.1 и TensorFlow 1.13.1.
Помимо этого, вам понадобится Python версии 3.6 и выше, TensorFlow и зависимости для StyleGAN:
conda create -n stylegan pip python=3.6
source activate stylegan
## TF:
pip install tensorflow-gpu
## TB:
python -c "import tensorflow as tf; tf.enable_eager_execution(); \
print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
pip install tensorboard
## StyleGAN:
## Установка зависимостей:
pip install pillow numpy moviepy scipy opencv-python lmdb # requests?
## Загрузка:
git clone 'https://github.com/NVlabs/stylegan.git' && cd ./stylegan/
## Тестовая установка:
python pretrained_example.py
## Файл ./results/example.png должен быть фотографией мужчины средних лет
Конфигурация
StyleGAN не поддерживает опции командной строки. Вместо этого нужно отредактировать train.py и train/training_loop.py:
train/training_loop.pyИсходная конфигурация указана в функции training_loop в строке 112.
Ключевые аргументы:
- G_smoothing_kimg и D_repeats — влияют на динамику обучения,
- network_snapshot_ticks — частота сохранения скриншотов,
- resume_run_id — установлен на "latest",
- resume_kimg — указывает на финальное значение разрешения создаваемых изображений.
Рекомендуется установить minibatch_repeats = 1 вместо minibatch_repeats = 5. Это делает обучение более стабильным и быстрым.
Обратите внимание, что некоторые из этих переменных переопределяются в train.py. Лучше определить их там, иначе вы можете сильно запутаться.
train.py (ранее config.py в ProGAN, переименован run_training.py в StyleGAN 2)Здесь устанавливается количество графических процессоров, разрешение изображения, набор данных, скорость обучения, горизонтальное отражение/ увеличение данных и размеры мини-пакетов. Этот файл включает в себя настройки, предназначенные для ProGAN — следите за тем, чтобы случайно не включить ProGAN вместо StyleGAN и не запутаться.
Скорость обучения и размер мини-пакетов можно не менять. Но разрешение изображения, набор данных и зеркалирование необходимо установить:
desc += '-faces'; dataset = EasyDict(tfrecord_dir='faces', resolution=512); \
train.mirror_augment = True
Мы установили разрешение изображений размером 512 пикселей для набора данных dataset/faces, включили зеркальное отражение и задали заголовок для контрольных точек и логов, который теперь появится в results/ в строке '-faces'.
Если у вас нет 8 графических процессоров, вам необходимо изменить значение -preset и указать количество ваших GPU. StyleGAN не станет автоматически выбирать правильное количество графических процессоров. Он попытается использовать несуществующие графические процессоры и после выдаст сообщение об ошибке. Обратите внимание, что в CUDA используется нулевое индексирование, то есть GPU:0 указывает на первый процессор, GPU:1 на второй и так далее. Как выглядит сообщение об ошибке:
tensorflow.python.framework.errors_impl.InvalidArgumentError: \
Cannot assign a device for operation \
G_synthesis_3/lod: {{node G_synthesis_3/lod}}was explicitly assigned to \
/device:GPU:2 but available \
devices are [ /job:localhost/replica:0/task:0/device:CPU:0, \
/job:localhost/replica:0/task:0/device:GPU:0, \
/job:localhost/replica:0/task:0/device:GPU:1, \
/job:localhost/replica:0/task:0/device:XLA_CPU:0, \
/job:localhost/replica:0/task:0/device:XLA_GPU:0, \
/job:localhost/replica:0/task:0/device:XLA_GPU:1 ]. \
Make sure the device specification refers to a valid device.
[[{{node G_synthesis_3/lod}}]]
Для 2×1080ti автор установил:
desc += '-preset-v2-2gpus'; submit_config.num_gpus = 2; \
sched.minibatch_base = 8; sched.minibatch_dict = \
{4: 256, 8: 256, 16: 128, 32: 64, 64: 32, 128: 16, 256: 8}; \
sched.G_lrate_dict = {512: 0.0015, 1024: 0.002}; \
sched.D_lrate_dict = EasyDict(sched.G_lrate_dict); \
train.total_kimg = 99000
Запуск
StyleGAN можно запустить в GNU Screen и разделить его на несколько оболочек: 1 терминал для запуска StyleGAN, 1 для TensorBoard и 1 для Emacs.
В Emacs можно открыть файлы train.py и train/training_loop.py для справки и удобного редактирования.
Последний патч для StyleGAN позволяет включить цикл while, чтобы нейросеть продолжала работу после сбоев, например:
while true; do nice py train.py ; date; (xmessage "alert: StyleGAN crashed" &); \
sleep 10s; done
TensorBoard — это утилита, позволяющая визуализировать записанные в ходе обучения значения, которые можно просматривать в браузере, например:
tensorboard --logdir results/02022-sgan-faces-2gpu/
# TensorBoard 1.13.0 at http://127.0.0.1:6006 (Press CTRL+C to quit)
Обратите внимание, что TensorBoard может работать в фоновом режиме, но его необходимо обновлять каждый раз при новом запуске, так как результаты будут в другой папке.
Обучать StyleGAN намного проще и надежнее, чем другие GAN, но это все же больше искусство, чем наука. Дополнительные советы по обучению от автора проекта вы можете найти на сайте.
Вот так выглядит процесс успешного обучения:
https://gwern.net/image/gan/stylegan/2019-03-16-stylegan-facestraining.mp4
Генерация аниме-изображений
После успешного обучения StyleGAN приступаем к самому интересному — созданию образцов!
Трюк с усечением
Трюк с усечением Ψ является наиболее важным гиперпараметром для всего поколения StyleGAN. Он используется во время генерации выборки, но не во время обучения. С помощью трюка усечения можно контролировать разнообразие генерируемых изображений. При Ψ = 0 разнообразие равно нулю, и все лица представляют собой одно глобальное усредненное лицо. При ±0,5 генерируется широкий диапазон лиц, а при ±1,2 вы увидите огромное разнообразие лиц и стилей, но также получите много искажений. Рекомендуется установить Ψ = ±0,7, это обеспечивает наилучший баланс качества и разнообразия картинок.
Случайные образцы
В репозитории StyleGAN есть скрипт pretrained_example.py для загрузки и создания одного лица. Однако его можно легко адаптировать для использования локальной модели и генерировать, допустим, 1000 выборочных изображений с гиперпараметром Ψ = 0,6, что даст качественные, но не очень разнообразные изображения. Они будут сохраняться в results/example-{0-999}.png:
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
def main():
tflib.init_tf()
_G, _D, Gs = pickle.load( \
open("results/02051-sgan-faces-2gpu/network-snapshot-021980.pkl", "rb"))
Gs.print_layers()
for i in range(0,1000):
rnd = np.random.RandomState(None)
latents = rnd.randn(1, Gs.input_shape[1])
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
images = Gs.run(latents, None, truncation_psi=0.6, \
randomize_noise=True, output_transform=fmt)
os.makedirs(config.result_dir, exist_ok=True)
png_filename = os.path.join(config.result_dir, 'example-'+str(i)+'.png')
PIL.Image.fromarray(images[0], 'RGB').save(png_filename)
if __name__ == "__main__":
main()
Видео
Самый простой способ получить видео процесса обучения — сделать скриншоты прогресса и конвертировать их в видеозапись. В ходе обучения размер скриншотов растет по мере увеличения качества и детализации, и в конце может быть довольно большим. Поэтому стоит выполнить сжатие с потерями или преобразование в JPG. Чтобы превратить множество снимков в обучающее видео, можно использовать FFmpeg:
cat $(ls ./results/*faces*/fakes*.png | sort --numeric-sort) \
| ffmpeg -framerate 10 \ # показываем 10 изображений / сек
-i - # stdin
-r 25 # выходная частота кадров; кадры будут дублироваться до 25 fps
-c:v libx264 # x264 для совместимости
-pix_fmt yuv420p # заставить ffmpeg использовать стандартное
# цветовое пространство
-crf 33 # адекватное качество
-vf "scale=iw/2:ih/2" \ # уменьшаем изображение в 2 раза,
# т. к. полная детализация не требуется
-preset veryslow -tune animation
./stylegan-facestraining.mp4
Загрузка готовой модели
Вы можете загрузить готовую модель StyleGAN с размером изображений 512 пикселей, обученную на 218794 лицах в течение примерно 38 GPU-дней.
Перенос обучения
Одна из самых полезных вещей, которую можно сделать с обученной на большом массиве данных моделью — это использовать ее в качестве стартовой площадки для ускорения обучения другой модели на меньшем количестве данных. Модель StyleGAN, создающую аниме-лица, можно переобучить так, чтобы она генерировала только рыжеволосых, мужчин, либо же конкретных героев. Для этого понадобится примерно 500-5000 новых картинок, но в некоторых случаях достаточно и 50.
Перенос обучения происходит довольно просто. Для этого достаточно обработать новый набор данных и просто начать обучение с существующей моделью. Обработайте изображения так, как описано выше. Далее отредактируйте training.py, изменив параметр -desc для нового набора данных. После запустите train.py и начните перенос.
Основная проблема заключается в том, что повторный запуск обучения не может начинаться с нулевой итерации. В этом случае StyleGAN игнорирует предварительно обученную модель и запускает обучение заново. Чтобы этого избежать, сразу укажите высокое разрешение. Например, чтобы начать с размера изображения в 512 пикселей, установите resume_kimg=7000 в training_loop.py. Тогда StyleGAN будет вынужден загрузить предыдущую модель. Чтобы убедиться, что вы всё сделали правильно, до переноса обучения проверьте первый образец (fakes07000.png или какой-нибудь ещё): он должен выглядеть как исходная модель в конце обучения. Затем последующие обучающие образцы должны показать, что оригинал быстро трансформируется в новый набор данных.
Так выглядит перенос обучения StyleGAN на конкретного персонажа — Холо из аниме «Волчица и пряности»:

Другой пример — Сорью Аска Лэнгли из «Евангелиона»:
https://gwern.net/image/gan/stylegan/2019-02-21-stylegan-asukatransfer-interpolation.mp4
Теперь, если вам понадобится портрет в стиле аниме или уникальная аватарка, то вы сможете сгенерировать ее самостоятельно. А на этом сайте вы можете сделать из фото аниме — тоже с помощью нейросети!
С оригинальной статьей можно ознакомиться по ссылке.



